The Cost of Logging in 2022

Editor's note: In 2016 NearForm Chief Software Architect, Matteo Collina, wrote a popular post about the Cost of Logging which introduced the newly released Pino logger to the world. 5 years, 238 releases, 8.6k stars in github and millions of downloads later, we felt it was time to update some of the information from that original post. Below you will find updated information and links to Pino resources.
The Cost of Logging in Modern Applications
Nowadays, all applications use logs to record everything that happens in a request/execution, however, choosing the right log library is essential if you are looking for high performance. In some cases, choosing an unoptimized library can reduce the application throughput by 80%!
This blog post is an updated version of “The cost of logging - 2016” .
Essentially, it is necessary to establish a baseline for any performance optimisation. It will serve as a comparison for the rest of the benchmarks you will see in this post.
All the snippets were grouped in this repository .
Measuring Throughput
Consider a simple express application:
'use strict'
const app = require('express')()
app.get('/', function (req, res) {
res.send('hello world')
})
app.listen(3000)Baseline measurement without logging
In order to measure this, we will use autocannon , an HTTP/1.1 benchmarking tool inspired by wrk and built in Node.js:
$ autocannon -c 10 -d 60 http://localhost:3000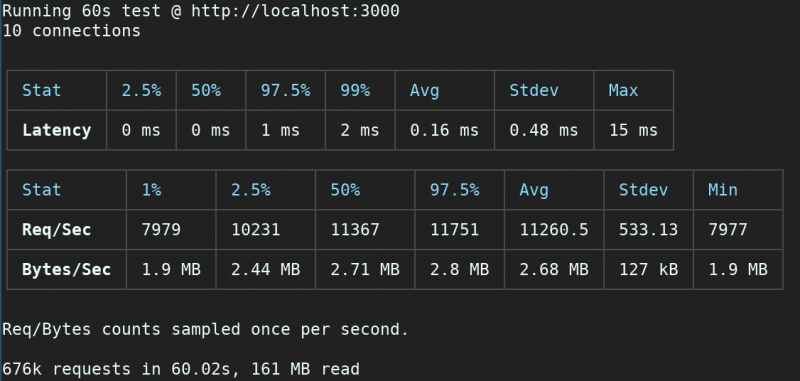
Logging with Bunyan
Let’s see what happens when we add logging. In all of the following examples, we will be redirecting the output from stdout to /dev/null:
'use strict'
const app = require('express')()
app.use(require('express-bunyan-logger')())
app.get('/', function (req, res) {
res.send('hello world')
})
app.listen(3000)We would expect this to have similar throughput to the first one. However, we got some surprising results:
$ autocannon -c 10 -d 60 http://localhost:3000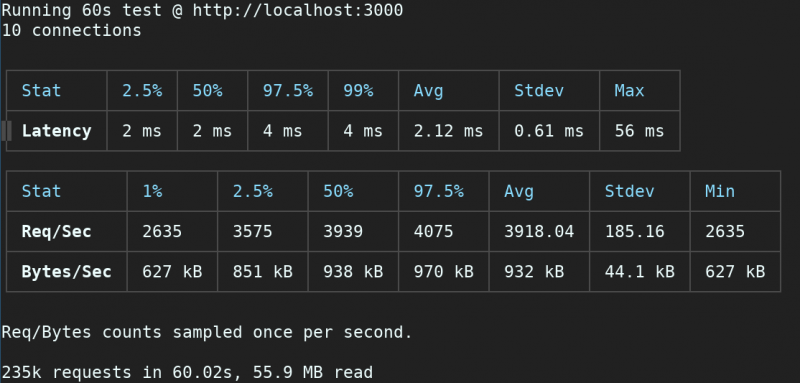
Running a server using bunyan for logging will reduce throughput by almost 70%.
Logging with Winston
Winston yields slightly better results:
$ autocannon -c 10 -d 60 http://localhost:3000
Running a server using Winston (version 2) for logging will slow you down by almost 50%.
Introducing Pino
Our logger is Pino , which means pine in Italian. Matteo Collina, the author of Pino got the inspiration for the name from a pine tree in front of his house.
Pino is the fastest logger for Node.js (full benchmarks found here and here ). While you can use Pino directly, you will likely use it with a Web framework, such as express, hapi or fastify. Pino is (99%) API-compliant with Bunyan and Bole.
The Anatomy of Pino
Pino is a fast logger built on several principles:
1) Low overhead. Using minimum resources for logging is very important. Log messages tend to get added over time and this can lead to a throttling effect on applications.
2) It only logs in JSON.
3) It needs to be as fast as possible.
4) It supports child loggers, to allow transactions to have their own metadata.
5) Drop-in compatible API with bunyan, bole, winston wherever possible.
Instantiating Pino is easy:
'use strict'
const pino = require('pino')()
pino.info('hello world')
pino.error('this is at error level')
pino.info('the answer is %d', 42)
pino.info({ obj: 42 }, 'hello world')
pino.info({ obj: 42, b: 2 }, 'hello world')
pino.info({ obj: { aa: 'bbb' } }, 'another')
setImmediate(function () {
pino.info('after setImmediate')
})
pino.error(new Error('an error'))
const child = pino.child({ a: 'property' })
child.info('hello child!')
const childsChild = child.child({ another: 'property' })
childsChild.info('hello baby..')Pino was originally created at NearForm (see the old blog post for further details) and it was designed to be a fast JSON logger.
Using Pino with Express
Let’s consider the following example using express-pino-logger :
'use strict'
const app = require('express')()
const pino = require('pino')
const dest = pino.destination({ sync: false, dest: '/tmp/test.log' })
const logger = pino(dest)
app.use(require('express-pino-logger')({ logger }))
app.get('/', function (req, res) {
res.send('hello world')
})
app.listen(3000)We can run the same benchmark as before:
$ autocannon -c 10 -d 60 http://localhost:3000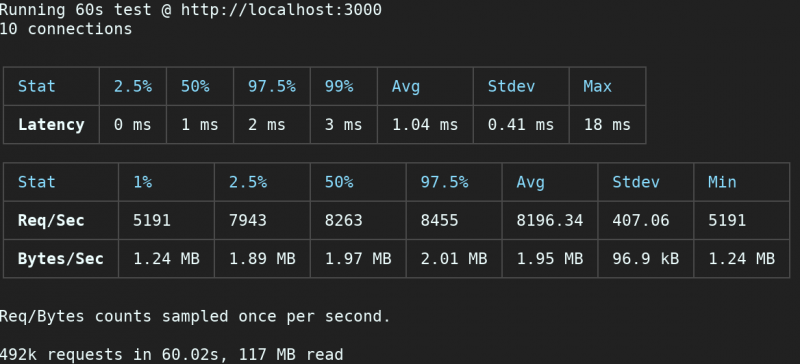
Using express-pino-logger increases the throughput of express-winston by almost 40%.
Asynchronous Logging
Most of the logging libraries available define synchronous logging as the standard mode. The messages are directly written to the output stream as they are generated with a blocking operation.
Asynchronous logging works by buffering the log messages and writing them in larger chunks.
This can improve your application performance by executing the I/O operations in a different context. Asynchronous logging has consistently lower latency than synchronous loggers.
In the Pino.js Benchmarks you can see the comparison between both approaches:
The following values show the time spent to call each function 100.000 times.
Pino Average: 246.336ms PinoAsync Average: 129.507ms
Asynchronous and Synchronous Logging Benchmarks with Fastify
To bring this information to reality, we can use Fastify , which comes bundled with Pino by default, as a benchmark example between asynchronous and synchronous logging on HTTP servers.
const Fastify = require('fastify')
const pino = require('pino')
// Just change to "false" to make it async
const dest = pino.destination({ sync: true })
const logger = pino(dest)
const fastify = Fastify({ logger })
fastify.get('/', async () => 'hello world')
fastify.listen(3000)Synchronous logging:
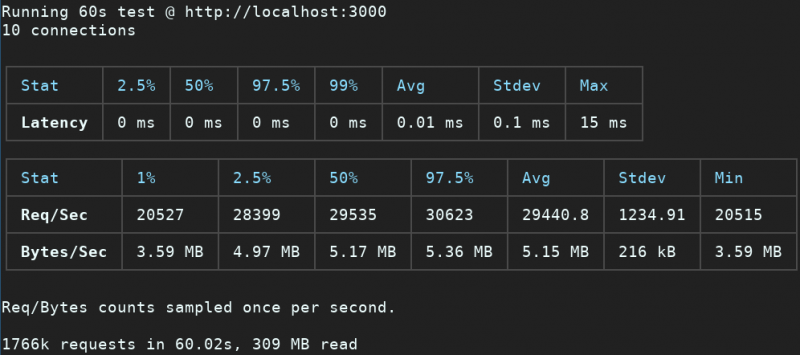
Asynchronous logging:
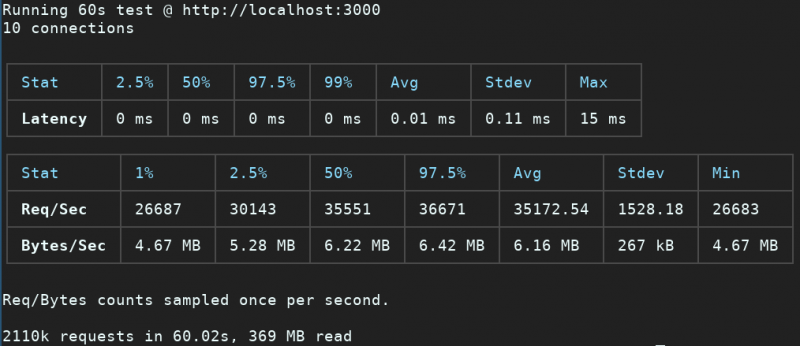
We get around 20% more throughput when using Asynchronous logging.
A Real-world Logging Scenario
Nonetheless, a raw benchmark would not show the importance of the async approach. For that reason, let’s move it to a real-world scenario:
Let’s assume that your application is serving a huge quantity of requests, and each one of those requests is logged at least twice (start request and end request).
Limitations of the Synchronous Approach
In the synchronous approach, the logging waits for the write to complete before executing the next operation. This could potentially compromise the performance of your application.
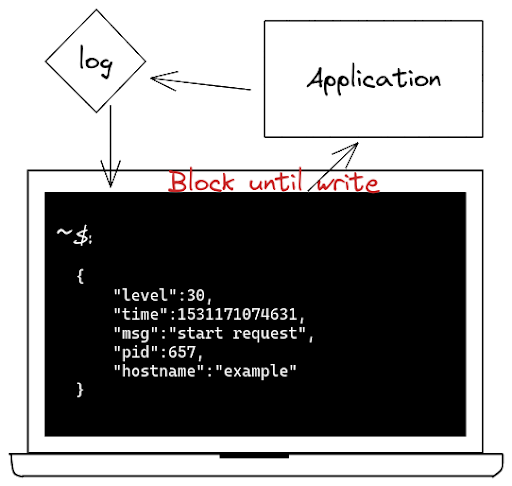
This is the most common issue when dealing with synchronous operations, but, let’s look at one more complicated issue.
The EAGAIN Error
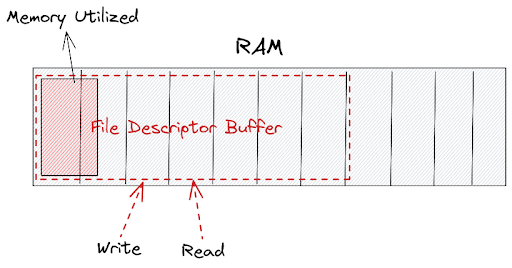
Usually, those logs are redirected to a file descriptor and in that situation, it is not uncommon that the memory buffer reserved for the file descriptor becomes full.
What usually happens in that situation?
The EAGAIN error is emitted by the operating system and it means the resource (file descriptor) is not available now and prompts users to try again later.
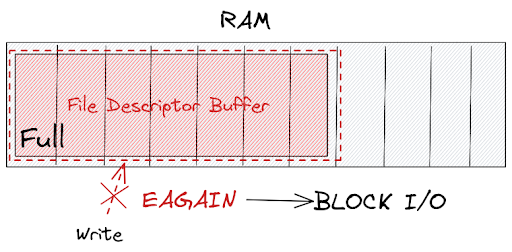
When dealing with synchronous communication, it will lead to a blocking operation and obviously a bottleneck.
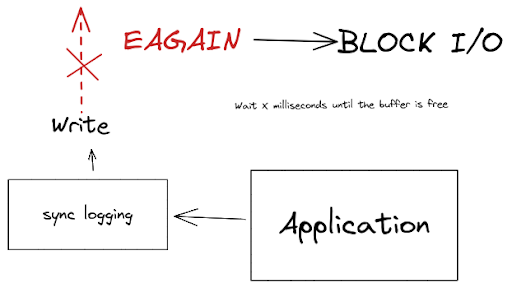
Avoiding Bottlenecks with pino async
In this situation, the pino async can avoid major headaches, because it will not block the I/O when an error occurs, instead, it will keep the log in the buffer until the file descriptor is ready to write.
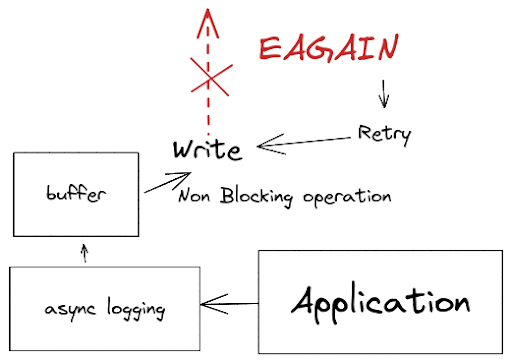
It is important to understand that if the file descriptor takes too much time to free, the buffer could grow the application memory until an out-of-memory is thrown.
For that reason, Pino allows you to manage the buffer queue through settings in `sonic-boom` (retryEAGAIN) and you can limit the queue to avoid out-of-memory through the maxLength option.
Hence, in a real-world comparison, asynchronous logging might be essential to your architecture.
Besides the above explanation, I strongly recommend checking the “ Welcome to Pino@7.0.0 ” blog post. It mainly explains the `pino.transport()` feature (necessary to work with asynchronous logging).
The Pino family
Pino has a set of companion tools, each of which has been meticulously implemented to have a minimal impact on performance:
- sonic-boom: Extremely fast utf8 only stream implementation
- thread-stream: A streaming way to send data to a Node.js Worker Thread.
- fast-redact: Pino’s redaction functionality is built on top of fast-redact.
- fastify: The Fastify web framework comes bundled with Pino by default.
- safe-stable-stringify: Safe, deterministic and fast serialization alternative to JSON.stringify.
The Pino Ecosystem
- express-pino-logger: use Pino to log requests within express.
- koa-pino-logger: use Pino to log requests within Koa.
- pino-arborsculpture: change log levels at runtime.
- pino-caller: add callsite to the log line.
- pino-clf: reformat Pino logs into Common Log Format.
- pino-debug: use Pino to interpret debug logs.
- pino-elasticsearch: send Pino logs to an Elasticsearch instance.
- pino-eventhub: send Pino logs to an Event Hub.
- pino-filter: filter Pino logs in the same fashion as the debug module.
- pino-gelf: reformat Pino logs into GELF format for Graylog.
- pino-hapi: use Pino as the logger for Hapi.
- pino-http: easily use Pino to log requests with the core http module.
- pino-http-print: reformat Pino logs into traditional HTTPD style request logs.
- pino-multi-stream: send logs to multiple destination streams (slow!).
- pino-mongodb: store Pino logs in a MongoDB database.
- pino-noir: redact sensitive information in logs.
- pino-pretty: basic prettifier to make log lines human readable.
- pino-socket: send logs to TCP or UDP destinations.
- pino-std-serializers: the core object serializers used within Pino.
- pino-syslog: reformat Pino logs to standard syslog format.
- pino-tee: pipe Pino logs into files based upon log levels.
- pino-toke: reformat Pino logs according to a given format string.
- restify-pino-logger: use Pino to log requests within restify.
- rill-pino-logger: use Pino as the logger for the Rill framework.
For further information check the Pino Ecosystem .
Pino is scalable
Pino is the fastest logger in town (see the benchmarks ), and it uses a full set of performance optimisations to achieve this goal, from avoiding JSON.stringify, to rolling our own printf style formatting module .
These techniques reduce the overhead of logging by 40%.
In extreme mode, we also delay flushing to disk, to reduce it even more, by 60%.
We have adopted Pino in some projects, and it has increased the throughput (req/s) of those applications by a factor of 20-100%. Stay tuned for more blog posts on the techniques that Pino uses to be so fast, as each of those has its own story.
Editor's note: Matteo Collina also contributed code review, examples and guidance on this post.
Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact