Accelerate your enterprise’s access to data insights with lean data platforming
Adopting a lean data platform enables your data engineers, analysts and scientists to focus on creating valuable insights for your enterprise

Data platforms are a key component in any organisation looking to drive decision-making and insights from their data. With the rise of concepts like data mesh, many organisations are on long data transformation journeys — which can take time. Traditional data architectures need significant ongoing effort to both maintain and develop, slowing down the time to deliver insights. Could adopting lean principles help transform how value and insights are derived from your data?
A lean data platform embodies lean software principles. It focuses on efficiency, cost, scalability and, most importantly, value. Let data engineers, analysts and scientists focus on creating insights. They shouldn't be weighed down by managing complex infrastructure. Popular cloud service providers (CSPs) such as AWS provide the means to do this with the plethora of serverless, fully managed services available at your disposal.
Nearform has created a data lake accelerator which builds upon the extensive data offerings provided by AWS. It applies lean principles and helps our clients focus on what matters when it comes to their data.
In this article, we will explore what it means to build a lean data platform, the key principles and benefits, as well as how the Nearform data lake accelerator utilises these principles to drive insights forward while keeping costs under control.
Applying lean principles to data platforms
Lean comes from the manufacturing industry and was pioneered by Toyota in the 1950s/60s to reduce waste and inconsistency in their processes. Since then, lean has been widely adopted in other fields, including software development. It shares similar philosophies with agile.
In the upcoming sections, we will cover each of the seven lean software development principles and apply them to a data platform. We will also touch on how our data lake accelerator utilises some of the principles to drive efficiency and value. But before then, we’ll share some AWS service definitions because it’s the CSP we reference in this article.
AWS service definitions
For our accelerator, we’ve chosen to use the native AWS data engineering toolset, but comparable services exist from all the major CSPs. To best align with lean principles, we’ve chosen tools that are, wherever possible, fully managed, serverless services. This helps reduce the code artefacts we need to deploy, maintain and monitor — along with reducing overhead running expensive instances of computing and storage.
The services we’ll be referencing in this article are as follows:
AWS Lambda: Serverless, event-driven function service. Great for small workloads such as validating the contents of a file, archiving old data or for ingesting data via an API.
AWS Glue: Fully managed serverless ETL (extract, transform and load) service. Well-suited to large workloads using either PySpark or Python such as aggregations or joins. Also provides a data catalog as well as data quality capabilities.
AWS Step Functions: Serverless orchestration service that works with other services to coordinate and sequence events in your data pipeline.
Amazon Athena: Serverless query service that queries object-based data in S3.
Amazon S3: Resilient object storage service.
AWS Lake Formation: Managed service for setting up data lake security and governance.
Amazon CloudWatch: Monitoring and observability service for AWS services and workloads.
Amazon QuickSight: Serverless business intelligence (BI) service. Used for creating dashboards and reports easily.
Amazon SageMaker: Fully managed machine learning (ML) service for the deployment, testing and building of ML models.
We’ll now get into the seven lean software development principles.
Principle #1: Eliminate waste
In the context of a data platform, waste can manifest itself in many forms. This could range from wasted compute time to bloated storage costs with inefficient pipelines. Adopting a serverless approach is one great way to optimise performance and reduce waste. Since serverless scales to zero, you are reducing waste on the environment as well as waste on your wallet — you only pay for what you use. AWS Glue and AWS Lambda are two services that utilise this approach.
Let’s contrast this to a more traditional data warehouse utilising dedicated servers and scheduled ETL jobs to process data in batches.
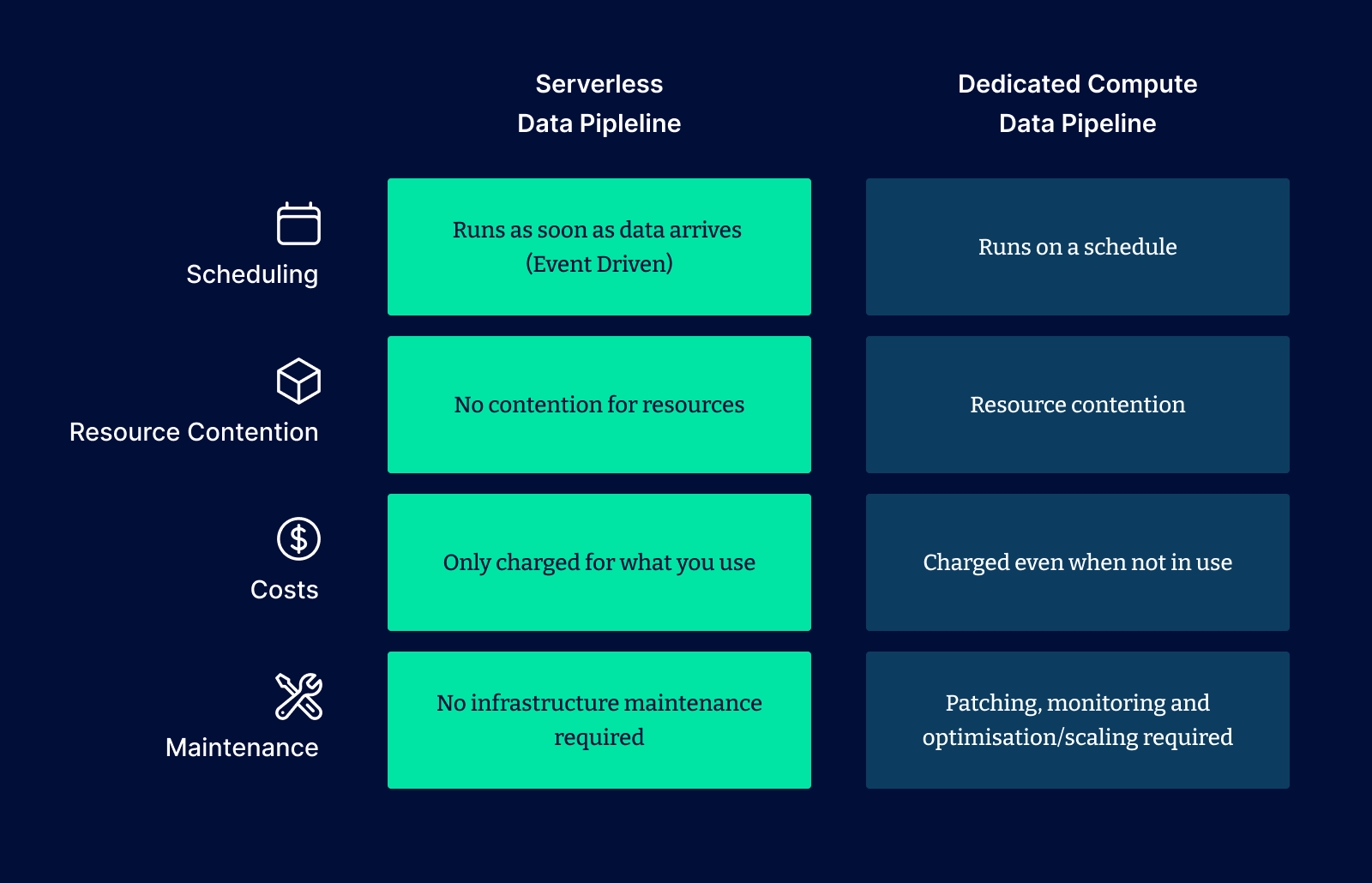
Serverless data pipeline VS dedicated compute data pipeline
As you can see from the above comparison, adopting a lean approach can be ideal for eliminating waste in your data pipelines. But what about storage?
Lifecycle policies can be another great way to eliminate waste, as cloud object storage offerings typically include functionality for automatically archiving or deleting data. This saves on engineering time and effort as well as cost, by demoting old data to cheaper storage tiers over time.
You can also optimise the time your engineers spend working on repetitive and manual activities. Time is a crucial resource, so it’s critical that development processes and tooling are optimised with this in mind. For example, using CI/CD to ensure that testing and infrastructure deployment run automatically is a great way of reducing waste for an engineering team. This ties in nicely with “deliver as fast as possible,” which we will cover later.
The Nearform data lake accelerator uses many of the approaches outlined above to make your data platform lean. Out of the box, we provide templates for serverless data processing using a combination of AWS Glue, AWS Lambda and AWS Step Functions for orchestration, meaning that you can provision your end-to-end data pipeline using serverless compute.
Principle #2: Amplify learning
A lean data platform should enable continuous feedback and improvement for both its developers and end users. Continuous improvement is a well-established part of agile practices and helps us get the most out of our teams and data. Promoting a culture of experimentation and failure will help teams improve the quality and speed at which they deliver data products. This could be a machine learning model serving recommendations via an API or a business intelligence dashboard.
Designing and building your platform with modularity at the centre means that components or services can be changed or removed without affecting the entire system.
Utilising the sharing capabilities in BI tools such as QuickSight to quickly share your analysis work can be another way of amplifying the learnings from your data across the business. These tools give organisations visibility over previously inaccessible data.
An example is demand forecasting. Teams can leverage current and historical data to understand drivers of demand and patterns for growth. Insights can then be easily shared to improve awareness and enable individuals across the business to contribute to data-driven decisions. Or you can utilise the embedded analytics capabilities that QuickSight offers to integrate analytics alongside existing applications. This means that business users can benefit from increased exposure to data as part of existing workflows and tooling.
Principle #3: Decide as late as possible
Much like with software development, data pipelines can come with some uncertainty — whether that is with requirements or with changes to input data. Having flexibility in your platform to make changes means that you don’t need to make assumptions prematurely, resulting in a reduction in costly refactoring or inefficiencies.
Utilising modern capabilities such as schema-on-read and having the ability to evolve your schemas automatically using technologies like Apache Iceberg, in conjunction with automated data cataloging services like AWS Glue crawlers, means that not only will your schemas evolve automatically but so will entries in your data catalog.
The Nearform data lake accelerator utilises both Apache Iceberg and Glue crawlers out of the box for data processing. This means that ingestion from source data can be dynamic and it gives engineers the choice to decide “as late as possible” what they want to do with changes and updates to schemas or new files.
Decisions on your compute and infrastructure commitments can also be deferred by adopting a lean approach. Serverless technology enables you to delay these decisions and offers ways to save costs too. AWS Glue Flex can save you around 30% (at the time of writing) on your compute bills for Glue Jobs by being more flexible with job start times. This is ideal for overnight batch jobs.
Principle #4: Deliver as fast as possible
Delivering goods “just-in-time” (JIT) is a core concept of lean in the manufacturing sector. This is similar to the delivery of insights to business stakeholders. Making information available when it’s needed to support decision-making, rather than being available in large batches that arrive too late to be useful. Being able to deliver data quickly can result in significant benefits especially if the data is time sensitive.
Building a data platform that utilises an event-driven approach provides the flexibility to scale up to real-time levels of event processing. This can be critical in applications or use cases that are extremely time-sensitive, such as fraud detection. This can also be extended to more advanced patterns like event sourcing, or to terabyte-scale streaming datasets using tools like Amazon Kinesis. In the case of more batch-oriented datasets, AWS Glue allows you to allocate around 1000 vCPU cores and 9TB memory to a single Spark compute job.
There may also be scenarios where ad hoc analysis makes the most sense to deliver value as fast as possible. In these cases, give analysts or engineers tooling like interactive notebooks to make calculations quickly across large datasets. Amazon Athena provides interactive Spark notebooks in addition to its existing SQL capabilities. This combined with QuickSight means visualisations can be created in minutes. This all means that insights can be derived at speed without needing to wait for a new data pipeline to be built.
Principle #5: Empower the team
This principle applies to data platforms in the same way it does to traditional software development. By empowering your team members, you are enabling them to make informed decisions. This means not only giving people the confidence and freedom to make those decisions, but also providing them with the tools and ability to do so.
A large part of data engineering is empowering non-technical teams to consume the data produced by the business, and give them the tools to make better-informed decisions. Business intelligence tools are fantastic for this. Our data lake accelerator uses Amazon QuickSight as the BI tool of choice. Some non-technical teams will struggle to convert from the tool they are most familiar with — an expert Microsoft PowerBI user may not be comfortable transitioning to another tool.
It is important to remember that all the major BI tool providers have great interconnectivity between data lakes from all the major CSPs — so PowerBI will very happily report on an AWS data lake.
From a technology perspective, we want to create self-service capabilities, allowing team members to access the data they need with minimal friction. Giving users the power to self-serve is key to reducing wasted time. This, combined with the on-demand query capabilities of a tool like Amazon Athena, means that analysts have instant access to data.
We’ve highlighted a number of AWS tools that align with this principle, but one of particular note here is Lake Formation. Lake Formation centralises data governance. This comes in the form of permissions management, data classification and data sharing. By using a tool like Lake Formation we can empower the team. Giving teams autonomy to share and control data with features like tag-based access control means that the right people get instant access to new data as it becomes available without needing to submit requests or wait for approvals.
Principle #6: Build integrity in
Data integrity is a key part of building any data platform. Data should be accurate, reflect the real world and be void of errors, unnecessary duplicates or inconsistencies. Additionally, data should be consistent, both in its structure but also the speed at which it arrives (timeliness). Having data with integrity means that business users can trust the outputs or insights being produced. This can be critical in the success of a data platform, as inconsistent or abnormal results are likely to erode trust. Setting up processes and tooling is important to reduce the chances of this occurring.
Testing is a powerful way of improving data integrity on your data platform. Having data pipelines written in a way that makes testing frictionless improves reliability by catching errors or mistakes earlier. For example, we can verify that a transformation has been applied correctly, or that files have been written in the way they should be. Writing tests as data pipelines are built also enables regression testing. For instance, if an upstream system or part of the same pipeline changes, we can be confident there will be no unintended consequences.
Data quality can be thought of as an additional way of testing data. As opposed to testing the behaviours, this can be another excellent method for identifying anomalies or errors in your data. Simple checks can be implemented using tools like Glue Data Quality to, for example, check that "column x has values between 0 and 100’" Adopting this, plus testing with a "shift left" mindset, means that mistakes are found early. Engineers or stakeholders can be alerted and decisions made before the data affects downstream systems or users.
Security is another key element of integrity. Data platforms should implement robust security measures to protect data, audit and control access. These measures ensure compliance with data protection regulations such as GDPR or CCPA and build on the other measures we mentioned earlier. AWS provides several solutions to enable this, primarily IAM (identity and access management). The principle of least privilege can be applied to only allow users access to the specific resources required to fulfil their duties. Lake Formation can define detailed access controls and audit data. So, you have complete control over your data.
Principle #7: Optimise the whole
In software development, “optimise the whole” refers to optimising the entire value stream, as opposed to a single component or process. This concept also applies to data pipelines. If you are building pipelines, it's important to understand the bottlenecks when approaching optimisations. Making optimisations to a job or service that do not have a material impact on the overall processing time is unnecessary. Engineers should look to utilise monitoring and observability tooling to aid with this. AWS provides a plethora of tools to help, namely Amazon CloudWatch.
With CloudWatch, you can collect and aggregate metrics/logs from data pipelines and use these to create alerts and dashboards. You can then use these to assess where optimisations need to be made. For example, it might be that the pipelines are not the issue and there could be a problem with generating reports. The Nearform data lake accelerator provides CloudWatch dashboards and alerts to help you optimise your data pipelines.
Over-optimisation can also be a problem. When performing an analysis of metrics and results, you should ensure that any optimisation efforts you undertake have a measurable return on investment.
Wrapping up
While some of the ideas we discussed here are not new, we believe that applying lean principles to your data platform can improve how you extract value and insights from your data. Nearform’s data lake accelerator utilises these principles to accelerate delivery for our clients, meaning they can continue to adapt and grow in the fast-changing data landscape. The accelerator also draws upon our proven experience with clients to build on the concepts we’ve mentioned throughout this article.
By eliminating inefficiencies in storage, computing and the development process, ambitious enterprises can also reduce costs whilst continuing to provide a responsive platform and services to consumers.
Self-service tools such as Amazon Quicksight, Athena and Sagemaker provide analysts and data scientists with the power to perform ad hoc analytics at scale. Automated scaling and data quality testing to reduce engineering time. Logging, monitoring and alerting from tools like CloudWatch mean that operations engineers can leverage a centralised view across the platform, helping them proactively identify and resolve issues.
Our data lake accelerator helps us to provide you with these capabilities and benefits. Contact Nearform to discuss how we can help you on your data journey.


Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact