Managing load in Node.js with under-pressure

The Fastify plugin under-pressure offers a simple solution to detect if a Node.js application is under load and apply a circuit-breaking mechanism.
When Node.js was created in 2009, it introduced a revolutionary programming model to the world of web applications. In a radical departure from the programming models of mainstream web servers such as Apache and Microsoft’s IIS, Node.js introduced reliance on a single thread for multiple requests. Most other web servers were using classic multithread-based pools, with each thread dedicated to serving only a single request at a time.
How was Node.js able to achieve this single-threaded approach?
The answer is based on asynchronous input-output. Most I/O operations were implemented in an asynchronous way, so that the main thread could pass a request’s I/O to the background and be ready to handle another. Once the background I/O operation was complete, the main thread would resume and complete the request/response cycle.
The Node.js approach has proven itself to be blazingly fast for a large set of use-cases needed by modern web applications.
You can read more about the Node.js threading model in Don't Block the Event Loop (or the Worker Pool) .
All the source code accompanying this article is available in nearform/backpressure-example .
Putting Node.js under pressure
Node.js is extremely efficient in serving HTTP requests, but there is a limit to its speed. In fact, it’s not difficult to slow down even a simple Node.js HTTP server by overloading it with more requests than it can handle.
To show these limits, we can create a barebones Node.js HTTP server and hit it with autocannon , a popular load testing tool. First, we install autocannon with npm:
npm install -g autocannonThen, we create our program in a file called http.js . This file will delay any request response by approximately 200ms, to simulate a time-consuming asynchronous operation happening in the background.
const http = require("http");</p><p>http
.createServer(function (req, res) {
setTimeout(function () {
res.end("hello world");
}, 200);
})
.listen(3000);We run the program in a terminal:
node http.jsAnd hit it with autocannon:
autocannon https://localhost:3000When the autocannon run completes, you will see several statistics about latencies and request rate.
The primary number we’re interested in is the 99% percentile of latency, as it represents the latency of most of the requests:
Running 10s test @ https://localhost:3000
10 connections</p><p>
┌─────────┬────────┐
│ Stat │ 99% │
├─────────┼────────┤
│ Latency │ 218 ms │
└─────────┴────────┘As long as our latency is around the 200ms mark, we’re looking good because that’s what we expect from our server.
[caption id="attachment_300014660" align="alignnone" width="600"]
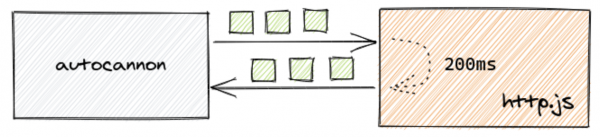
Figure 1: Load testing with autocannon[/caption]
An increase in latency would mean that the program is struggling to keep up with the number of requests it’s receiving.
Let’s see if we can put pressure on the application by increasing the load produced by autocannon:
autocannon https://localhost:3000 -p 100 -c 1000</p><p>Running 10s test @ https://localhost:3000
1000 connections with 100 pipelining factor</p><p>┌─────────┬────────┐
│ Stat │ 99% │
├─────────┼────────┤
│ Latency │ 741 ms │
└─────────┴────────┘By hitting the server with 1,000 concurrent connections and telling each connection to send 100 requests before waiting for a response, we’ve been able to make the latency jump significantly. Requests that should complete in roughly 200ms are now taking more than 700ms.
[caption id="attachment_300014661" align="alignnone" width="600"]
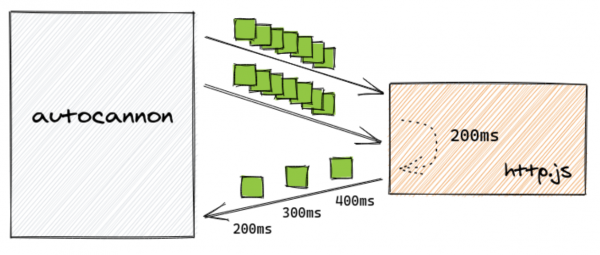
Figure 2. Increasing load on the application[/caption]
Our Node.js server is now taking on more work than it can handle.
Consequences of pressure
When this happens, we can clearly see a deterioration in the performance of the server. How can we deal with it?
Node.js has no built-in mechanism to avoid load, meaning that it will happily accept any number of requests and it will allow them to queue up and wait for their turn to be processed.
The real question is, do we want to allow this? If our purpose is to keep our system responsive we should probably find better ways to handle increasing workloads, perhaps by scaling our application.
Without going into the realm of infrastructure concerns yet, and keeping things at the application level, it is likely that when response times exceed a certain threshold, it means that our server shouldn’t keep queuing up requests because it may never be able to handle them in time for the client to process the responses.
In fact, by the time our server responds, clients may have already timed out, meaning that the server has done unnecessary work at a time when its processing power was most needed.
Causes of slowdown
In our earlier example, there were no application-related reasons for the slowdown; the server was simply receiving too much load, and the resources on the machine where it was running could not handle it.
In other circumstances, the high mark for the amount of load the server can handle is more likely influenced by real operations the application is performing. Common causes of slowdowns are:
- CPU-intensive work blocking the main thread, such as cryptographic operations or parsing/serialising JSON data structures.
- Interacting with resource-constrained external services such as Databases or APIs.
Detecting excess pressure
The first thing to do is identify the metric to use to detect that the application is receiving too much load. Depending on the scenario, we could use:
- Response times, based on how long we would normally expect our server to take to respond to requests and how long we want to make our users wait for a response
- Error rates, meaning that errors are happening in the system, possibly due to external services not responding in a timely manner and thereby causing requests to queue up in our server
- Application-level metrics — for example, the length of an in-application queue we use to perform tasks with a certain level of concurrency
To keep it simple and practical, let’s consider response times as the primary metric we will use to determine that we’re under pressure.
Collecting metrics
Now that we’ve determined that response times will be our reference metric to detect load, let’s see how we can collect this information.
We’ll use the Prometheus client for Node.js, available via the prom-client package. Furthermore, we’ll also start using a real web framework to simulate a more realistic application. Fastify is our framework of choice at NearForm.
We won’t go into the details of how to set up a Fastify application here, you can read the Fastify Getting Started guide to set up one, or you can use the example code provided.
const prometheus = require('prom-client')
const endTimer = Symbol('endTimer')</p><p>const metric = new prometheus.Summary({
name: 'http_request_duration_seconds',
help: 'request duration summary in seconds',
maxAgeSeconds: 60,
ageBuckets: 5
})</p><p>fastify.addHook('onRequest', async (req) => {
req[endTimer] = metric.startTimer()
})</p><p>fastify.addHook('onResponse', async (req) => {
req[endTimer] && req[endTimer]()
})</p><p>fastify.get('/metrics', (_, reply) => {
reply.send(prometheus.register.metrics())
})</p><p>fastify.get('/slow', (_, reply) => {
setTimeout(() => reply.send('hello world'), 200)
})In the above example:
- We instantiated a Prometheus Summary metric, which allows us to collect interesting statistics about request duration, specifically percentiles.
- The metric is used in Fastify’s request and response hooks to track request duration.
- We registered a /metrics endpoint that we can use to look at the metric itself in the Prometheus format.
- We reimplemented the earlier endpoint responding after approximately 200ms.
If we hit the application again with autocannon we can see the metrics exposed by the /metrics endpoint reflecting the response durations.
# HELP http_request_duration_seconds request duration summary in seconds
# TYPE http_request_duration_seconds summary
http_request_duration_seconds{quantile="0.01"} 0.0006875
http_request_duration_seconds{quantile="0.05"} 0.0006879672875
http_request_duration_seconds{quantile="0.5"} 0.0010178125
http_request_duration_seconds{quantile="0.9"} 0.06336875068888909
http_request_duration_seconds{quantile="0.95"} 0.19818964862222216
http_request_duration_seconds{quantile="0.99"} 0.214746601
http_request_duration_seconds{quantile="0.999"} 0.214746601
http_request_duration_seconds_sum 0.228651799
http_request_duration_seconds_count 14The metric is collecting and summarising all our data — awesome!
Even though we’re using a single custom metric to collect response times of our slow endpoint, there are more comprehensive ways to collect and expose Prometheus metrics in a Fastify application. In a real application we would use something like fastify-metrics , which also uses the same Prometheus client, but we’re keeping it simple here for demonstration purposes and to avoid adding unnecessary noise to the example.
Dealing with pressure
Now that we know request durations, we can decide what to do with them. To prevent our server from entering a situation whereby requests take longer and longer to process, we can put in place a circuit-breaking mechanism which causes the application to stop accepting requests when that happens. When the circuit opens, the server responds with an error status code, communicating back to the client that it cannot handle the request.
There are several ways we can do that, but for the sake of this article we will use under-pressure , an open source implementation of a circuit breaker for Fastify.
After installing it, we can then extend our earlier example by adding the snippet of code below:
fastify.register(require('under-pressure'), {
healthCheck() {
const three9percentile = metric.get().values[6].value</p><p> // four times the expected duration
return three9percentile <= (200 * 4) / 1e3
},
healthCheckInterval: 5000,
})under-pressure can be configured in different ways. In this case, we are using a custom health check, which reads the .999th percentile of our metric at intervals of 5 seconds and reports the status as unhealthy when its value exceeds the expected request duration by a factor of 4.
When that happens, under-pressure stops accepting requests and returns a 503 Service Unavailable error back to the client.
To try this, run autocannon with high enough values of concurrency and pipelining so that the slow endpoint takes longer than 800ms to respond. You can check how long the endpoint is taking by hitting the /metrics endpoint in a browser.
At that point, you will see the application returning errors as soon as it receives a request.
Closing the circuit
Once the circuit opens, it must be possible to close it again, otherwise the application will not be able to recover.
When we configured the Prometheus Summary metric, we provided a couple of options that enable this behaviour:
const metric = new prometheus.Summary({
name: 'http_request_duration_seconds',
help: 'request duration summary in seconds',
maxAgeSeconds: 60,
ageBuckets: 5,
})maxAgeSeconds and ageBuckets are the configuration options that allow the Prometheus client to use a sliding window, so that it only collects recent metrics data and it forgets about old data. Read more about this in the prom-client docs.
This also enables the application to recover after the circuit has opened. Because the application is not accepting any more requests, the metric wouldn’t have a chance to change and the under-pressure health check would keep reporting the app as unresponsive.
When the autocannon run that caused the circuit to open completes, the application will recover automatically after a while.
At the infrastructure level, this will allow us to detect that an instance of the application is unable to handle additional load and to exclude it from the load balancer, while dynamically scaling the number of running instances to handle the increasing load. We will focus on this in a later article.
Limiting the area of effect of the circuit-breaker
When the app stops responding because under-pressure has opened the circuit, the /metrics endpoint also starts returning 503 errors. This is clearly not what we want — only the slow endpoint should be affected by the circuit-breaker.
Achieving this in Fastify is simple enough, thanks to plugin scopes. Instead of registering the slow endpoint and under-pressure in the main application, we move their registration to a plugin. This will create a new scope and cause under-pressure to apply only to the routes that are registered in that plugin instead of the whole application. You can read more about Fastify plugin scopes in the official documentation .
Creating a safety net
In this article we’ve looked at a simple approach to detect when a Node.js application is under load and implemented a circuit-breaking mechanism. This preserves the health of the application and minimises the impact that a slowdown will have on the system.
We took a somewhat binary approach by rejecting requests as soon as we detected that the application was taking too long to respond. Though seemingly extreme, this approach provides the foundations for a more thorough and reliable scaling mechanism and serves as a safety net until our infrastructure can detect that we’re under load and take appropriate action.
Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact